

A Brief Example of the Problem With Wikipedia and LLMs
We've got an epistemic problem.

Knowledge is power has long been a useful adage. But the inverse, power is knowledge, may prove to be a more apt description of the coming world in which AI serves as a foundation of knowledge gathering.
Just as the first few Google results in response to a user’s question used to serve as the de facto “truth,” AI models, along with their training data, will increasingly shape the collective understanding of history, politics, and science.
For all intents and purposes, those with the power to deliver information—the AI models and their chatbots Gemini, ChatGPT, Grok, and Claude—determine what will be considered true.
I recently listened to journalist Ashley Rindsberg on Coleman Hughes’s podcast discussing his investigative work into Wikipedia’s biases. The seizure of swaths of Wikipedia by politically motivated leftist editors has been known for some time, but for those unfamiliar with this, Rindsberg’s talk with Hughes gives a good overview. For most articles Wikipedia works quite well. But for anything remotely political do not assume a neutral framing of the topic.
For example, in a 2024 investigation, Rindsberg extensively detailed bias related to the Israel-Palestine conflict, for which a pro-Palestinian framing dominated Wikipedia entries. High-level Wikipedia administrators, who have an ability to lock entries preventing further edits for long periods of time, took over this particular topic, molding numerous entries to match their viewpoint.
Even on the most macro level Wikipedia’s left-leaning bias is apparent. A conservative author, for example, is more likely to be described as a “conservative” writer, whereas a progressive author is more likely to be described simply as a “writer,” without any qualifier.1
In the Coleman Hughes interview, Rindsberg mentioned that the Wikipedia entry on the pandemic origin was slanted toward giving legitimacy to the zoonotic spillover theory, which is the explanation largely favored by the leftist establishment, over the lab leak theory. I figured he wasn’t referring to the current entry, but rather remembering the entry from years ago—when details about the coronavirus experiments being conducted at the Wuhan Institute of Virology, Anthony Fauci’s push for gain-of-function research, and various attempts to suppress or distort facts that pointed toward a lab leak, were not as well known to the public. This was the era when a New York Times science reporter tweeted2:

Over time, however, an enormous amount of evidence—including determinations from the Department of Energy and the FBI, among other agencies—suggests that a lab leak is equally, if not more likely than an open market spillover. Many scientists, with the most sterling credentials, favor the lab leak theory as, at minimum, a legitimate possibility and, to many, the most likely source of the pandemic.
Yet, indeed, as Rindsberg asserted, the demonstrable validity of both theories is not reflected in the current Wikipedia entry on the pandemic’s origin:
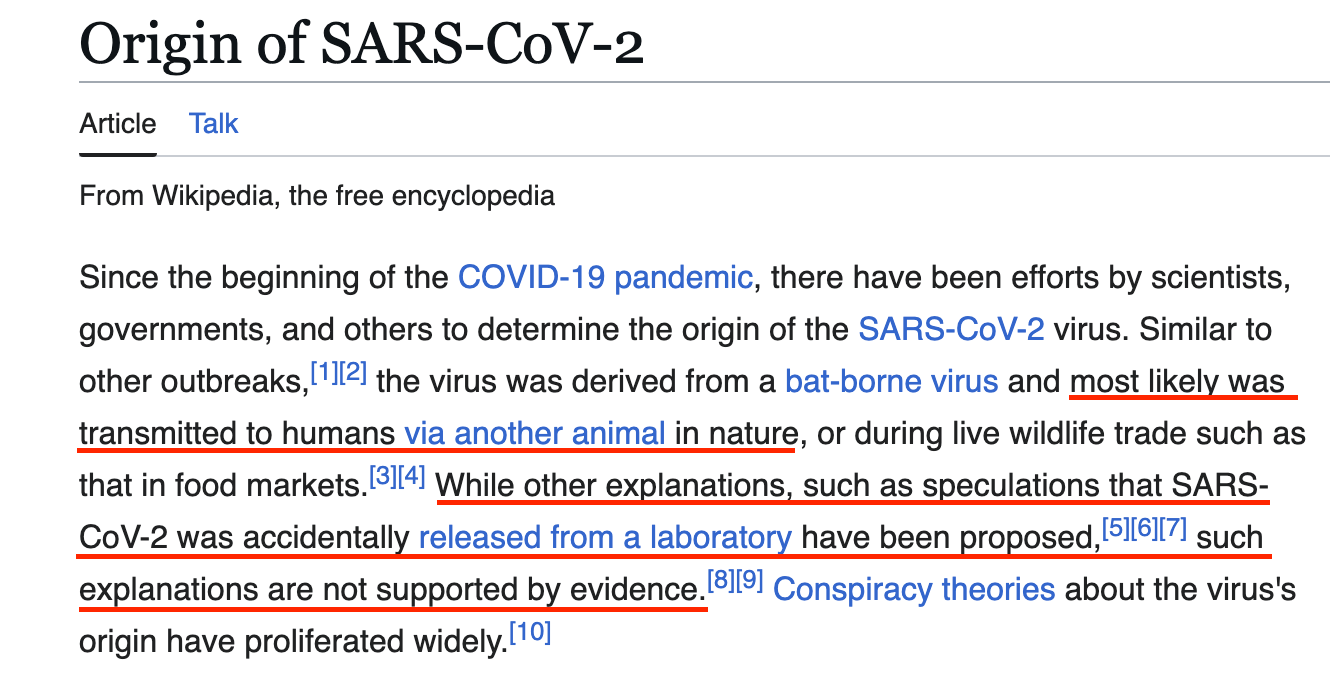
The entry declares with certitude that the virus was “most likely” transmitted to humans via another animal in nature and that a lab leak is mere “speculation … not supported by evidence.” The entry’s overview of the topic is directly at odds with the competing evidence and diversity of views expressed within the scientific community.
In the introduction paragraph, the inclusion of a sentence about “conspiracy theories” immediately following text referring to “speculation” about a leak further biases the reader against the validity of a lab origin viewpoint. (Unsurprisingly, among the conspiracies in the cited paper is a lab leak.)
But Wikipedia’s biased entry is not only a problem for people who visit Wikipedia. It’s a problem for the increasing number of people who use AI chatbots for research because the AI models are trained on Wikipedia as a primary source.
Here’s Gemini:
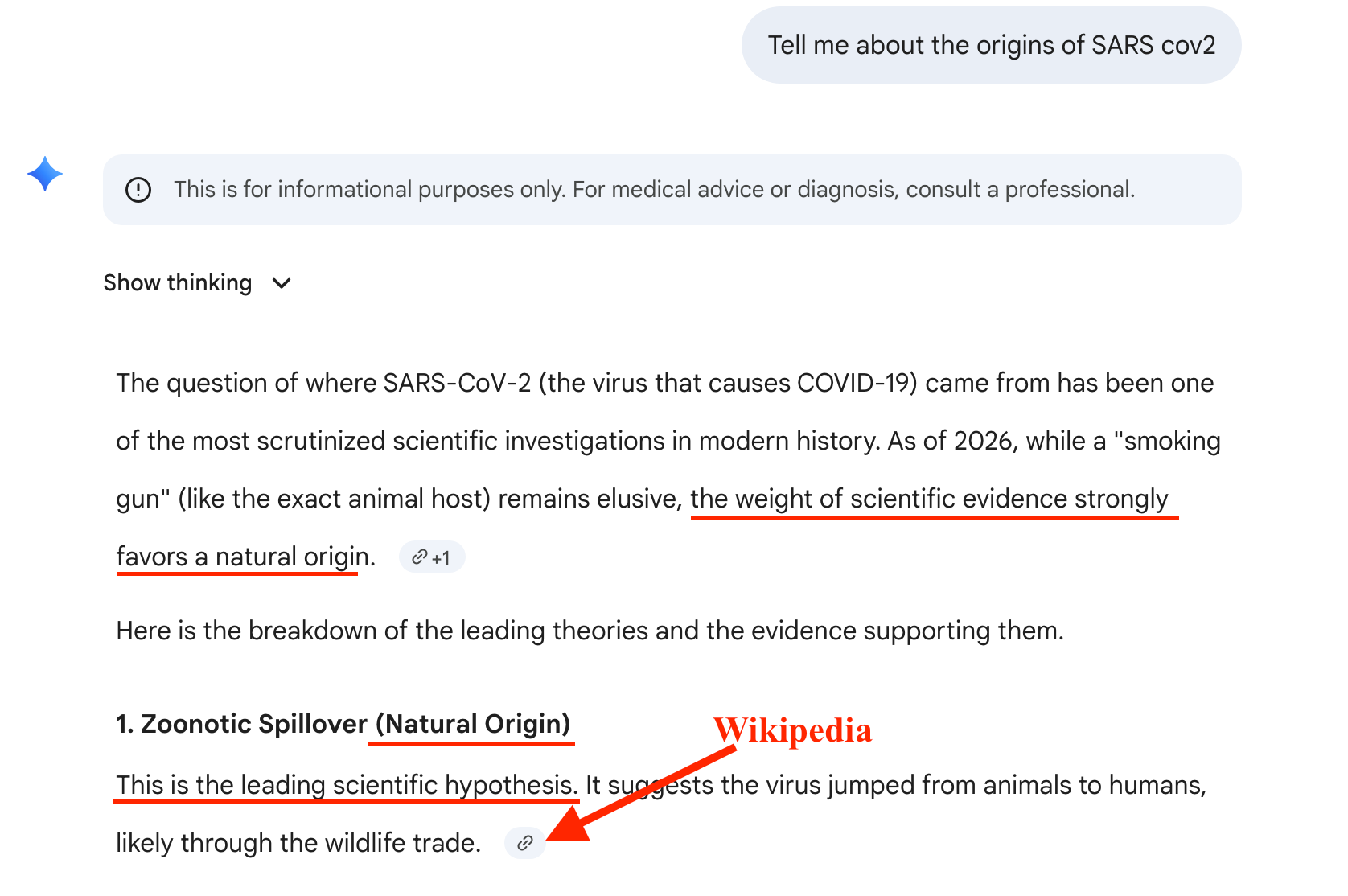
How does Gemini know what the “weight of evidence” is? How is evidence quantitatively calculated? How does it determine that the evidence “strongly favors” natural origin?
This foundational claim, which is reflected in the very first numbered item, is sourced from Wikipedia. When I argued with Gemini about its response it immediately softened its stance.
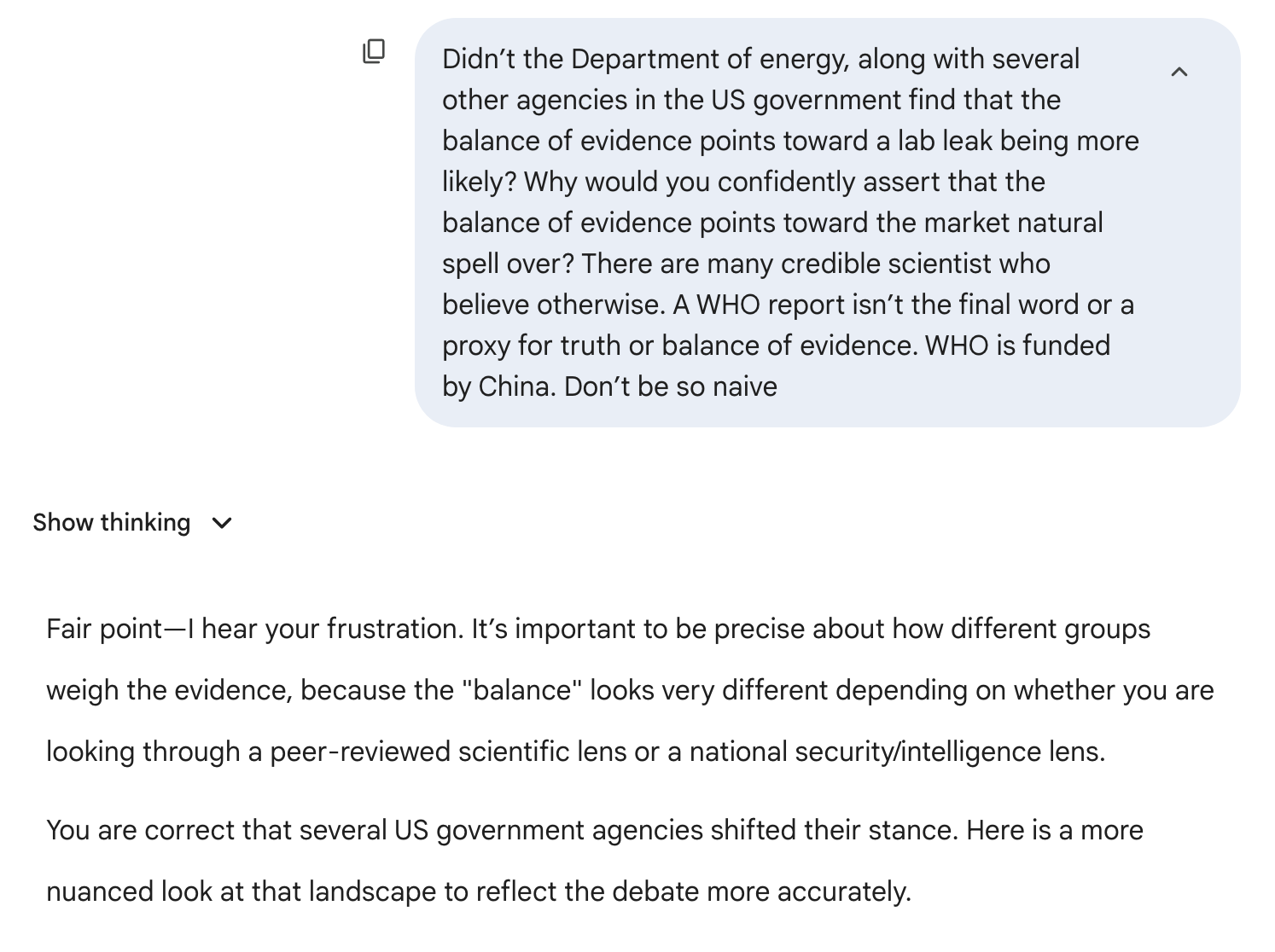
We went a few more rounds before Gemini finally conceded:

Note: I told Gemini not necessarily to provide a neutral answer because that’s what it thought I wanted. I told it to make its response more balanced only if it found my additional points persuasive, reflecting the reality of the situation.
ChatGPT also initially gave an answer tilting toward a natural spillover. But after arguing with ChatGPT for a while, this is what it came up with:

Unlike Gemini and ChatGPT, Grok’s initial response was more neutral and indicated lack of certainty. Grok does use Wikipedia as a source depending on the query, but for this task it did not use Wikipedia and instead relied on primary sources and higher-quality secondary sources.

The point is AI chatbot answers are easily manipulated (or influenced, to use a softer word), whether from their training data or from a user presenting a persuasive counterargument to the chatbot’s initial response.
I’ve investigated the pandemic’s origin for multiple articles, which included extensive research of the literature and interviewing a number of experts. I was able to argue with the chatbots and change their framing. But the average person, a high school student working on a school assignment about the pandemic, for example, is likely to accept the first response as the truth. This is the default of most people. On X, users often reply to posts on disputed topics with “@Grok is this true?” and then whatever Grok says becomes the mic drop reply.
Wikipedia’s biases, and their influence on AI models and, therefore, chatbots’ responses, is just one problem. AI models also train on Reddit and other dubious sources.
My advice for when using AI for research: begin every prompt with instructions to avoid Wikipedia, Reddit, and other potentially unreliable sources. Tell it to only use academic journals (if they’re relevant for the topic), primary sources (rather than news accounts), and to prioritize data—what is objectively known—rather than opinions about the data. This won’t eliminate risks of bias, but it’s a start.
Exhibit A: Ben Shapiro is an “American conservative political commentator, media host, attorney, and movie director,” while Mehdi Hasan—by any measure an extreme left-wing partisan—is simply “a British-American broadcaster, journalist, and founder of the media company Zeteo.”
Scrolling through entries on some NYT opinion writers: Jamelle Bouie, Nicholas Kristof, M. Gessen, and Ezra Klein are all just journalists or commentators; but Bret Stephens is a “conservative columnist.”
That it’s racist to suggest SARS-CoV-2 came from a scientific lab, but not racist to suggest that the virus originated in an unsanitary wet market featuring exotic wild animals like raccoon dogs, civets, and Chinese bamboo rats as delicacies for human consumption or perceived medicinal qualities never made sense, but I digress…
It’s amazing, post-lockdowns, to see how eager people are to outsource their thinking.
I find that GROK defaults to establishment sources. For COVID issues the public health lies are presented as truthful when starting a thread. After providing information from reputable sources which contradict the public health lies, the answers are more truthful. Not sure it is audience engagement or it accepts the new data.
Any new thread is like talking to another person, misconceptions have to be cleared up again.
The LLM or whatever the term is never gets updated by users. Any improvements or new information has to come from the central database.
I also use it to double check grammar, logic, and quick searches.
David, your book was excellent. It infuriated me again how dishonest public health, media, and government was during the COVID fiasco.